What I wanted was a way to answer a simpler question:
For a specific query, in a specific answer engine, how does my page's content compare to the content that engine is consistently surfacing?
A recent paper called E-GEO (Nov 2025) is one of the better pushes in this direction. It treats generative engine optimization (GEO) as something you can measure and improve systematically, rather than as a collection of writing rules. (ar5iv.org)
This post covers what that study suggests, then lays out a set of tests you can run to make AEO more concrete. If you already use Hi, Moose for AEO recommendations, think of this as the complementary "experiment loop" you can run when you want to validate changes with evidence.
How the E-GEO study is useful
E-GEO introduces a benchmark for "generative engine optimization" using thousands of realistic, multi-sentence queries that include intent and constraints. That matters because those long, context-heavy queries are closer to how people ask questions in answer engines. The study itself focuses on e-commerce (ranking products after retrieval). The part that maps cleanly to marketing work is the experimental mindset: control variables, run repeats, and measure changes.
A few takeaways worth borrowing:
- They tested a bunch of rewriting heuristics and found the results were mixed. Some helped, some didn't.
- They framed GEO as an optimization problem and used iterative methods to improve outputs.
- The optimized strategies converged on a fairly consistent pattern, which suggests there are repeatable "content traits" that models reward across topics.
The practical implication for marketers is not "copy this trick." It's that measured iteration beats guesswork when you're trying to influence a model's source selection.
What does "LLM-as-a-judge" mean?
When I say LLM-as-a-judge, I mean:
You give a model a fixed set of candidate pages (yours plus competitors), along with the query, and you ask it to judge or rank which page it would choose as the best primary source for answering that query.
The key idea is control.
- The judge doesn’t browse the web during the test.
- The judge isn't weighing you against everything online.
- The judge is only choosing between a fixed set of pages: your page and the competitor pages the engine is consistently citing for this query.
Is it perfect? No. But it's useful in the same way that user testing is useful. It gives you directional signal, quickly, as long as you run it like an experiment. Think of it as a proxy score for "how selectable our page is as a source" under controlled conditions, not a guarantee that we'll be cited in production.
Two important boundaries:
- This is an on-page/content-only test. The judge is only evaluating what's in the evidence packs and how extractable it is. In real life, selection can also be influenced by off-site mentions, topical authority, and brand trust.
- Models carry learned preferences from pre-training. Even in a controlled test, a judge may lean toward familiar brands, common phrasing patterns, or widely known concepts. How much you can shift that with on-page changes alone isn't always clear, another reason to run multiple trials and focus on consistent movement.
Why this is worth doing for AEO
Because it turns "does this change improve my AI visibility?" into a testable set of questions:
- If an answer engine had to quote one paragraph from us, which paragraph would it choose, and would that quote actually stand on its own?
- What would the engine cite us for? (definition, steps, comparison, pricing, template, examples) Or are we too generic to be "the source"?
- What is the "deciding detail" in the winning pages that we’re missing? (a rule of thumb, threshold, checklist, or specific recommendation)
- Are we giving the engine a clean way to pick us over a competitor, or are we saying the same things with different words?
- Which objections or edge cases are the winners pre-empting that we leave unanswered? (fit, "not for you if...", tradeoffs)
- Do we make it easy for the model to produce a confident answer, or does our copy force it to hedge?
- If the query implies a comparison, do we provide a decision frame the model can reuse? (criteria, matrix, "choose X if...")
- Are we burying the one thing people actually came for under context and setup? (and if we moved it up, would our rank change?)
- Are we missing "proof types" that models seem to reuse? (examples, mini case studies, numbers with context, cited sources, specific outcomes)
- Does our page contain "extractable anchors" the model can lift cleanly? (short sections, labeled lists, clear definitions, step sequences)
And it also forces a discipline many teams already have in CRO: keep variables tight, run multiple trials, look for consistent movement.
The AEO tests I think are worth running
These are the tests I'd run whether you use Hi, Moose or not. They are also the tests we designed our AEO A/B Testing Simulator around. I'm using "A/B testing" here in the experimental-design sense: same query, same competitor set, one variable changed, repeated trials, then measure the delta.
1. Multi-trial ranking, then report the median and the range
Single runs are noisy so run multiple trials and record the following:
- your median rank
- your best and worst rank
- how often you appear as a top pick
If your outcome swings a lot, that's not a failure. It's a signal that the judge is not seeing strong separating factors between candidates, or that your page is missing a few optimizations that could stabilize the selection.
What does "rank" mean here? (it's not the typical SERP rank, or position, we think of as SEOs and Marketers)
When I say rank, I am not talking about the order a model would show citations to a user. In this test, a rank is a controlled, internal leaderboard: we give the judge model the same competitor set and ask it to order the candidates by "most likely to be selected as a primary source for this query."
So the rank is a relative preference score inside the experiment and not a promise about real-world placement.
2. Controlled competitor sets for fair comparisons
If the competitor set changes every time you test, you can't accurately isolate whether your changes helped or not. Engines can surface slightly different sources across runs, which is why the goal is to sample multiple times up front and lock a consistent set for the experiment.
A practical approach is:
- capture the competitor set for a query by running multiple retrievals and keeping the sources that show up most consistently
- reuse the same competitor set while you iterate on your page
- treat the competitor set as fixed for the duration of the experiment, because changing it breaks the control and muddies the delta you're trying to measure
This is the AEO version of an A/B-style content test against a stable baseline.
3. "Why did I lose" gap analysis
A rank number alone, from an LLM judgement, isn't actionable. The useful part is a comparative explanation, the "why" from the judge. You are basically asking the judge "hey judge, what gives?"
or, hey judge... 🧑⚖️
- ...what do the top pages have that my page does not?
- ...what does my page have that is weaker or less explicit?
- ...what change would most likely change your opinion?
The best answers from the judge are specific: "Add a direct answer in the first 100–150 words that includes X and Y," beats "add more depth."
4. Direct answer placement and format
This sounds basic, but it is consistently high leverage.
For many queries, the pages that get chosen do two things early:
- they state a clear answer in a few sentences
- they define terms and constraints before expanding
Your goal is not to shorten the page. Your goal is to reduce the effort required to extract the answer, for both humans and LLMs.
5. Constraints and "not ideal if" sections
E-GEO's benchmark queries include constraints for a reason. Constraints are where pages differentiate.
A good pattern is a short section that covers:
- best for
- requirements
- constraints or tradeoffs
- not ideal if
This tends to make the content more "selectable" because it matches how people ask.
6. Proof objects
When pages win, they often contain "repeatable objects" that a model can safely carry into an answer:
- explicit feature lists
- quantified claims with context
- short customer quotes
- examples, templates, checklists
- comparison tables
You do not need a mountain of proof but you do need a few clean anchors.
7. Freshness signals that are visible
Freshness has two parts: updating content, and making recency easy to detect:
- last updated date (like many things with AEO, this has been important in SEO for several years)
- "as of [month year]" for anything time-sensitive
- changelog notes when it makes sense (we recently started doing this on the Hi, Moose homepage)
This is especially relevant for tools, pricing, and fast-moving categories.

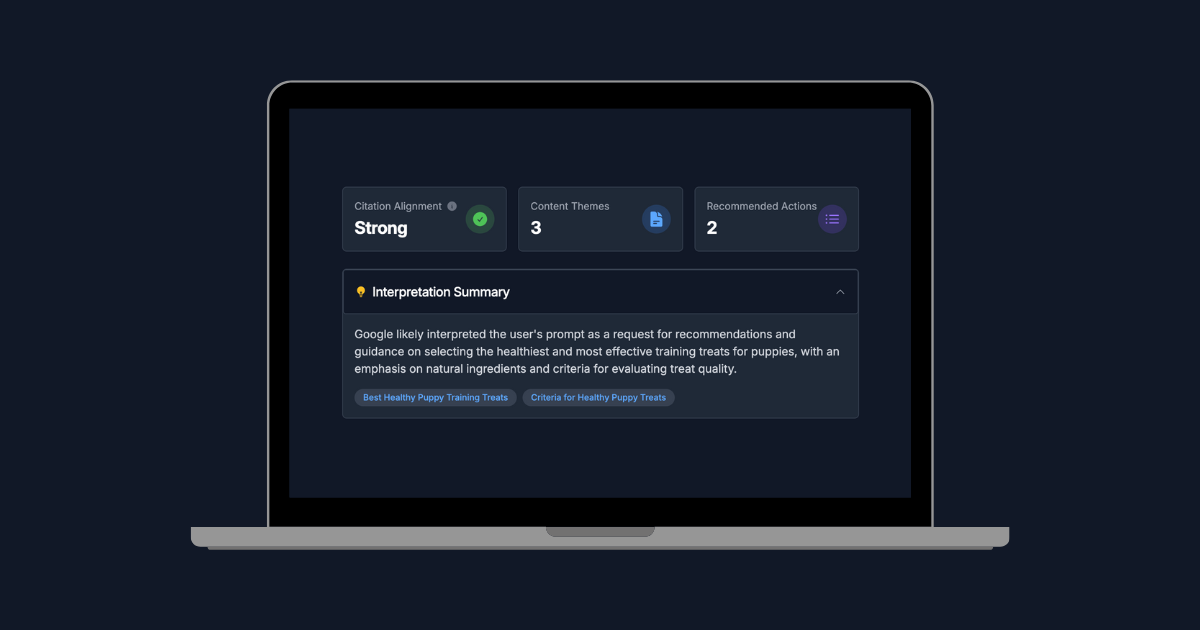
How we're using these ideas in Hi, Moose
Hi, Moose already has AEO guidance and recommendations that help you spot improvements quickly. The AEO A/B Testing Simulator is meant to complement that.
The simulator workflow is pretty simple:
- Enter a query and select an engine (ChatGPT, Gemini for AI Overviews / AI Mode, Perplexity).
- Capture the competitor set for that query (we execute the query multiple times to build a more complete set).
- Build compact "evidence packs" for each page so the judge has comparable inputs.
- Run multiple judge trials and summarize median rank plus stability.
- Generate plain-language explanations for why a page ranked where it did.
- Iterate and test the updated draft against the same competitor set to measure delta.
That's it, a workflow that's easy to repeat.
A practical way to start AEO testing today
If you want a lightweight version of this without overhauling your whole content process:
- Pick one query that matters to your business.
- Identify the top competitor pages that being cited by the target engine for that query.
- Create evidence packs (markdown files work), copy/paste your page content, and the competitor page content, each into their own markdown file.
- Create a prompt that establishes the judge, leaderboard, explanations, and provide constrains. Here's an example LLM-as-a-judge prompt.
- Run 3-5 judge trials, and note the "why" from the judge.
- Implement the top one or two fixes that show up repeatedly.
- Re-test with the same competitor set.
After a couple cycles, you'll have a repeatable pattern you can apply across more of your content.
If you want the "ready-to-run" version of this workflow, that's what we built into Hi, Moose's AEO Simulator, alongside the existing AEO recommendations and tooling.